以下文章来源于孤独大脑 ,作者老喻的
接《升维思考,降维行动》(上)
七
有时信仰束缚人的思想,有时信仰令思考者更加狂放。
对上帝的坚信,令牛顿在“解释宇宙”的时候,不会因为因果链条的某些缺失而停顿。
既然有“上帝”设计一切,他只管去探寻设计的规则就好了。引力到底是如何产生的?与距离的平方成反比到底是个什么东东?牛顿绝不纠结于探索路途中的“无知”,亦不因此陷入虚无主义。
爱因斯坦是未知论者,所以他要借助于斯宾诺莎的“万物之神”的力量。
而辛顿则有赖于“差异化的信仰”,用一生去赌相当长时间内毫无希望的神经网络。
莱布尼兹更复杂一些。他相信这个世界是所有可能世界中最好的一个,但什么是“所有可能的世界”?难道上帝在扔骰子吗?难道已知的宇宙还有另外的选项吗?
一方面相信“神的目的”,另外一方面,莱布尼兹则相信机械论的宇宙,并且这个宇宙是由不可再分的“单子”组成的。而令所有这些彼此不受影响的单子,经由上帝的算法,如钟表般稳妥地运行着。
理性主义的莱布尼兹作为十七世纪的全才,他发明了微积分,提出了二进制,制造出世界上第一台能做加减乘除的计算机器。
莱布尼兹坚信,能够建立起一种普遍的方法,“把一切正确的推理归结为一种计算”,这一思想成为现代计算机科学和人工智能的远祖,预示了“一切皆可计算”的未来。
如同原子论或者微积分的思想,计算机科学和人工智能通过将复杂问题拆解为简单的、低维的元素(0和1),然后再通过组合形成多维空间来解决更复杂的问题。
计算机通过将一切信息,无论是文本、图像、声音还是视频,都拆解为0和1的序列。
每一个0或1代表一个比特位,计算机通过这些比特位的组合,可以表示任何复杂的数据或结构。
这种拆解和组合的能力,是计算机处理复杂问题的核心。
就像在数学的微积分中,连续的函数被分解成无数个小的微小变化(微分),从而能够精确地理解和计算变化的累积效果,计算机科学的核心也是通过二进制(0和1)来表示离散信息,并进行高效的处理。
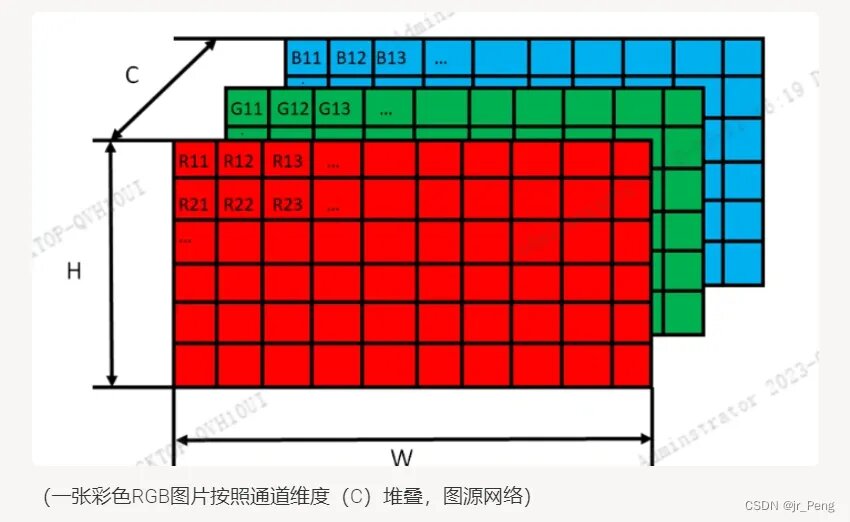
以图像数据为例,计算机将图像的每一个像素拆解为数值表示,其中每个像素的颜色信息通常以RGB通道表示。
对于一张224x224的彩色图像,它的表示形式为一个三维张量:224 x 224 x 3,其中:
• 224x224是图像的高度和宽度,表示每个像素的空间位置。
• **3个通道(RGB)**代表每个像素的颜色强度(红、绿、蓝)。
每个像素的颜色值本质上也是由0和1组成的二进制数字,这些数字通过不同的强度值(通常是0到255的范围)来编码颜色。
如上,这是将一维的比特组合成更高维的空间,从而能精确表示颜色、位置等信息。
这种构建方式类似于通过多维度理解现实问题,AI也能够通过维度的扩展与降维操作,更深入地解析复杂的现实世界。维度是处理复杂问题的关键工具。
人工智能的起源可以追溯到公元前400年,哲学家如柏拉图和亚里士多德提出,大脑在某种程度上类似于一台机器,利用内部语言编码知识,通过逻辑推理选择行动,这为人工智能的可行性奠定了思想基础。
此后,数学家们引入了运算逻辑和概率推理的工具,进一步推动了对计算和算法的理解。
20世纪中期,AI开始从理论走向实践,随着技术进步,AI从最初的基于布尔逻辑的推理,逐渐转向概率推理和数据驱动的机器学习。
这一转变显著提升了AI的复杂问题处理能力,推动了实际系统的功能改进,并与其他学科深度融合,使人工智能逐渐成熟为一个多学科交汇的领域。
辛顿此生对“神经网络”有一种偏执狂般的投入。这个过程漫长而跌宕。
20世纪中期,神经生物学家大卫·休伯尔和托斯坦·威泽尔通过实验揭示了大脑视觉系统的分层处理机制:
辛顿受到的启发是:大脑通过分层处理逐步提取信息,人工神经网络也可以模仿这一过程。
他意识到,神经网络可以像大脑那样,使用多层结构从低级特征(如像素或边缘)到高级特征(如对象或面部识别)逐层抽象。
辛顿在1986年提出的误差反向传播算法,使多层网络的训练成为可能,但其真正突破是在2006年,他通过“逐层预训练”有效地克服了深层神经网络训练的困难。
继续我们自由的类比,深度学习可以自己发现维度,自己定义维度,甚至不用对人解释--有些也解释不了。
传统的机器学习依赖人工定义和选择特征,而深度学习通过多层神经网络逐层自动学习,提取数据中的高层次特征。
这一过程不需要人为介入,可以从低级信息(如像素、声音波形)中逐步提取出更抽象的特征(如物体、语义)。这种自动化极大减少了特征工程的复杂性。
每一层的神经网络通过对低维度信息的处理和组合,提取出更高维的特征,最终形成对数据的全面认知。
正如爬山、解谜、搭建乐高或绘画的过程一样,深度学习通过分层抽象,让计算机能够自动从简单到复杂、从具体到抽象地理解世界。
在机器学习和神经网络中,维度通常指的是特征空间的大小。
我们输入的每一个数据点(无论是图像、文本还是其他形式的输入)都在一个高维空间中表示。
类似于毒酒问题中将100桶酒用7个二进制位表示,在神经网络中,模型将复杂的输入数据映射到一个更紧凑的表示空间中,确保通过最低的维度表示出最多的信息。
我们来通过一个实际的简单例子,描述大模型和Transformer的工作原理。
假设我们要用一个Transformer模型来完成一个常见任务:翻译一句简单的英文句子到中文。句子是:“I love cats.”
1. 输入的准备:将句子转化为向量
Transformer模型不能直接处理文字,它需要将输入的句子“I love cats.”转化为向量(数字形式)。这一过程称为词嵌入(Word Embedding)。
• 词嵌入的过程:每个词都会被转换成一个高维向量。例如,假设模型使用768维的向量,那么每个词都会用一个768维的向量来表示。这些向量不仅仅是随机数字,它们包含了词的语义信息。例如,“love”和“like”在语义上相近,它们的向量可能相似。
因此,句子“I love cats.”被转换为以下向量序列:
• I → [0.5, 0.2, ... , 0.8](768维向量)
• love → [0.3, 0.9, ... , 0.1](768维向量)
• cats → [0.7, 0.4, ... , 0.2](768维向量)
通过将每个词转换成高维向量,模型可以更好地表示每个词的复杂含义和它与其他词之间的关系。
这就是升维思考的第一步:将简单的文字映射到更高维度的空间,从而捕捉它们的复杂语义和语境信息。
2. Transformer的自注意力机制
接下来,Transformer模型 使用其核心机制——多头自注意力机制 来处理这个向量序列。
自注意力机制帮助模型理解每个词与句子中其他词的关系,并为每个词在句子中的重要性分配不同的权重。
• 自注意力机制会为每个词计算它与句子中其他词的关系。例如:
通过这种关系的计算,模型可以更好地理解整个句子的结构和含义。
♦ “I”和“love”有关系(主语和谓语)。
♦ “love”和“cats”有关系(动词和宾语)。
• 多头自注意力机制:每个注意力头关注句子中的不同关系。例如:
♦ 一个注意力头可能专注于“love”和“cats”之间的关系。
♦ 另一个注意力头可能专注于句子的整体结构,比如“主语—动词—宾语”的模式。
这些注意力头会从不同角度理解句子的每个词,使模型能够生成一个更全面的表示。
类比一下:我们可以将注意力机制类比为毒酒问题中的侍卫,每个侍卫负责检查一个特定的桶。
每个注意力头就像一个侍卫,负责检查输入中的特定模式。最终,模型通过多个“头”捕捉到句子中的丰富信息,类似于侍卫通过喝酒推断哪个是毒酒。
3. 基于概率的输出生成
输出生成是基于概率分布的。在每一步翻译过程中,模型并不是直接生成一个确定的翻译,而是计算每个可能翻译的概率分布,并选择概率最高的词作为输出。
• 例如,当模型要翻译“love”时,它会计算多个可能的翻译,并生成以下概率分布:
模型会选择概率最高的词“爱”作为翻译。
♦ “爱” → 85%的概率
♦ “喜欢” → 10%的概率
♦ 其他翻译 → 5%的概率
概括而言,大模型之所以能够在多个任务上表现出色,主要是因为它们通过大量数据学习到了丰富的高维表示。
这些表示能够很好地捕捉输入数据中的模式和复杂关系。
相比于传统模型,大模型的高维表示具有更好的泛化能力,能够在不同任务之间迁移学习。
为什么大语言模型像最聪明的人那些,能够学习不同领域的知识,并且可以自由迁移?
这些大语言模型所做的是寻找共同的结构,通过发现共同结构,它们可以用更有效的方式对事物进行编码。
让我给你一个例子,如果你问GPT-4"为什么堆肥堆和原子弹类似",大多数人都无法回答,他们认为堆肥堆和原子弹是完全不同的事物。
但GPT-4会告诉你,虽然能量和时间尺度不同,但它们都涉及链式反应,当堆肥堆越热就会发热越快,当原子弹产生的中子越多,产生的中子就越快,所以它们其实都是链式反应的形式。
许多人觉得大模型不过是在拼凑人类已有的知识,辛顿认为这是错误的。对此我深感认同。我最喜欢向ChatGPT问的问题,经常与打比方有关。
现实世界中,许多人假装自己是聪明人,但是有两点最难伪装:打比方的能力,和幽默感。
辛顿认为大模型能够理解知识的本质(至少是从人类角度定义的“本质”),并且把“这种理解压缩到了它的权重参数中”。
尽管语言模型已经表现出相当的空间推理能力,但引入多模态处理将使这些模型获得更深层次的理解和推理能力。
多模态模型整合了来自不同感官的信息源——如图像、视频、声音、甚至机器人操作——这使得模型能够不仅仅依赖语言来学习世界。
多模态模型使得机器可以像人类一样,在更复杂的“维度”中进行操作。
例如,当模型能够通过视觉看到一个物体,并通过模拟或物理操作与该物体进行交互,它就会更直观地理解物体之间的空间关系和物理规律。
这种转变相当于将AI从一个符号处理的世界提升到了一个接触现实的高维世界,从而让AI更好地理解物理世界中那些难以用语言描述的复杂概念。
随着AI技术的不断发展,我们不仅在追求更强大的计算能力,更是在探索“何为智能”的本质问题。
从莱布尼兹的普遍计算设想,到当下的大模型和多模态,世界似乎正在逼近一个神秘的边界——那就是对世界的全面认知,这认知可能不仅仅来自算法,更或许是人类与机器在复杂维度中的共同演化与创造。
以上“五、六、七”三节,我们探讨了人类如何理解世界以及何谓“看到”和“知道”。
休谟通过怀疑因果关系和实体的观念,提出了经验主义的核心观点:
人类在理解世界时,实际上是通过感官所获取的印象,将这些印象进行组合、记忆和反思,从而形成对事物的认知。
而洛克则进一步区分了第一性质(物体的固有属性)和第二性质(通过感官与物体交互产生的属性),为我们提供了一个系统的框架,解释了人类如何通过经验识别和分类物体。
这种基于经验和感知的认知方式,似乎为现代人工智能提供了某种隐喻——机器通过算法,尤其是大模型和神经网络,也在执行类似的感知任务。
机器学习模型不具备人类经验的复杂性,但它们通过多维特征的整合和分类,能够在模糊信息中找到概率上的最佳解。
这种“经验”不再依赖于人类的主观感受,而是通过庞大的数据和概率统计进行决策。
随着大模型的出现,人工智能通过比特世界中的多维计算,在某种程度上复制了人类从经验中学习的过程。
就像我们在面对一个苹果时,通过颜色、形状、味道等特征将其归类为一种特定的水果,机器也通过将复杂信息降维为高维向量来完成分类和推理。
贝叶斯推理等技术帮助机器在不确定性中进行推断,模拟了人类在因果关系模糊时依赖概率推理的方式。
然而,大模型带来的不仅仅是经验的复制,它通过升维思考进入了更高层次的智能探索。
大模型能够通过多层神经网络提取出超越人类感知的特征,不仅是在我们所理解的空间内“看到”世界,还能在我们无法直接感知的高维空间中进行推理和决策。
正如我们前面所讨论的,AI通过“高维空间”在信息上实现了穿墙破壁,仿佛成为了能够超越感官局限的存在。
从最初的人类经验主义出发,我们通过大模型进入了一个新的认知维度,也标志着人类对理解世界的新方式:
我们不仅依赖感官经验,通过数学和定律,经由推理和实验,还借助AI来拓展我们的认知边界,进入那些我们无法直观感知的高维领域。
尽管大模型能够通过高维向量解析复杂的现实,捕捉无数的特征和模式,甚至超越人类的感知范围,但它仍然受限于我们所提供的数据和算法规则。
我们所逼近的,并非上帝的视角,而是人类所能构建的最复杂、最精确的理解工具。
在不断的升维过程中,我们确实拥有了窥见更多维度的能力,但真正的“上帝算法”或许仍然超越我们所能触及的范围。
我们依然处于对宇宙深层次奥秘的探索阶段。通过AI和大模型,我们能够在多维空间中捕捉到更多的细节,重点也许不是找到终极答案,而是维度的突破。
大模型以及之后的AI,是帮助人类完成爱因斯坦的一样的宇宙认知革命,还是说我们不再需要人类的知识结构和因果推理?
毕竟,爱因斯坦是一位坚定的因果信徒。并非是他不接受概率化的方法,而是不相信上帝只是在扔骰子。即使是扔骰子,那是一颗什么样的骰子?
在相对论的框架中,爱因斯坦提出物质不仅能影响空间,还能重塑四维时空。
太阳并不像盒子里的保龄球那样静止不动,而是像床垫上的保龄球,压在织物上,扭曲了周围的时空区域。因此,当一颗行星绕太阳运行,或一个苹果朝地球的方向坠落时,它们并不会陷入某种牛顿引力无法解释的痛苦之中,只是在沿着阻力最小的路径穿过一个弯曲的四维空间而已。
“物质告诉时空该如何弯曲,而弯曲的空间则告诉物质该如何运动。”
也许,我们会用一种混合了碳基生物和硅基生物智慧优势的模式,继续扩展地球文明智慧的边界。
理论上,一百万只猴子胡乱敲打键盘,一定有一只能够创作出莎士比亚的剧作。但是,这个时间却要比宇宙的生命还要长。
那么,为什么地球上会出现一个叫莎士比亚的人,创作出那么多剧作?
我的这个思想实验,一定会有概率上的先后设定问题。即使如此,下面的答案依然是有利于人类的:
因为莎士比亚并不是一个在键盘前随机敲打的猴子,他是基于全体人类的一个知识模型来创作的,包括语言,符号,传说......甚至可能还夹杂有尼安德特人在篝火旁的故事。所有的在地球上存活的人,都从概率的角度,帮助了一个叫莎士比亚的人消除了杂乱,100%地创作出伟大的作品。
(The significant problems we face cannot be solved at the same level of thinking we were at when we created them.)
关于思维或者认知的维度,我不打算做一些老生常谈的陈述。
围棋是最复杂的游戏之一,规则却很简单,在一个19✖️19的二维格子上,演绎出比宇宙间所有原子数量还要多的变化。
20世纪最伟大的两个棋手之一吴清源,在晚年提出了“六合”围棋。
所谓“六合”,指的是四方(东南西北)和天地(上下)。
吴清源认为:棋的一子一子必须和所有的方面相和谐,追求的是恰到好处地处于当时的位置。
不止是重视中腹,六合之棋的“天地”之维度,超出了棋盘平面的二维世界。
围棋很有趣--由于棋子并不具备可移动性(除非被吃),围棋的过去和现在是被压缩在一个坐标化的棋盘上的。
理解并区隔围棋的厚势与实利,与许多重要的智慧“同源”。
20世纪最伟大的两个棋手之二李昌镐,有一个被广泛误读的名言:
也许这个话题值得另外写一篇。对此我的一个简单解构是:
那么,假如有一手棋的效率是51%,另一手棋的效率是81%,如果代价是一样的,为什么要选择51%的,而不是81%的?
对于一个职业棋手而言,每一盘棋的目标是非常明确的:
他所说的51%,其实是关于局部最优和全剧最优的取舍:
某一手棋A,就局部效率而言,是51%,全局效率是81%;
另一手棋A,就局部效率而言,是81%,全局效率是71%。
李昌镐尤其擅长在领先的局面下,迅速缩短战线,把棋盘“变小”。他会主动走一些看起来不是最优的招法,但是却能消除掉那些不确定性因素,从而把优势变成了胜势。
吴清源和李昌镐的秘密,都与爱因斯坦的四维时空宇宙观有相通之处--
在围棋这样一个基于二围棋盘的游戏中,他们比对手有着维度之上的碾压优势。
杨振宁曾在纽约州立大学石溪分校遇到一个15岁的学生,这个孩子非常聪明,轻松地回答了他提出的几个量子力学问题。
杨振宁接着问他:这些量子力学的问题,哪一个你觉得是妙的?
然而,他却讲不出来。“对他讲起来,整个量子力学就像是茫茫一片。”
杨振宁对他的看法是:尽管他吸收了很多东西,可是他没有发展成一个Taste。
“......学一个东西不只是要学到一些知识,学到一些技术上面的特别的方法,而是更要对他的意义有一些了解,有一些欣赏。
假如一个人在学了量子力学以后,他不觉得其中有的东西是重要的,有的东西是美妙的,有的东西是值得跟别人辩论得面红耳赤而不放手的,那我觉得他对这个东西并没有学进去。“
杨振宁说在西南联大七年,对他一生最重要的影响,是对整个物理学的判断,已有自己的Taste。
接下来这些内容稍显多余,但是对于教育的启示太大了:
• 杨振宁自幼喜爱观察自然,表现出强烈的爱美之心与好奇心。
• 父亲是数学家,杨振宁从小接触数学书籍,打下了扎实基础。
• 在西南联大期间,受到名师教授数学、物理及中文阅读与写作。
• 杨振宁的学术启蒙得益于吴大猷和王竹溪两位导师,分别引导他进入对称原理与统计力学领域。
所以,Taste像是一个人认知世界的多元思维中的高维鸟瞰,未知世界里隐秘的关联--哪怕只是关联的投影。
我们可以说,乔布斯是个很有Taste的人,这不是指艺术上的Taste,或是品味上的Taste,而是他能够横跨科技、艺术、商业,来做出一个超越时间的判断。
前面说的吴清源的对围棋的天才感觉,也是一种Taste。
也许每个人在获取知识和发展认知的过程中,都是在构建和训练一个自己的大模型。
所谓的Taste,就是在”茫茫一片“的神经网络之中,形成的某些石破天惊的重要连接。
Transformer通过自注意力机制,允许模型在不同维度上“看到”数据之间的相关性,提取出最关键的连接。
同样地,Taste也是通过对信息的深刻理解,能够超越表面,找到那些石破天惊的关键连接。
因此,Taste不仅是一种对知识的理解,更是一种超越时间和空间、对事物本质的高维度判断。
然而,如果没有Taste,不可能问出了不起的问题。
最近一段时间,有些人鼓吹硬科技,重理轻文。可如杨振宁所说,如果没有Taste,而总是追求有用,可能很难走得远。
“在一定程度上而言,科学家对自然深层次美的领悟和热爱,以及所具备的形而上的审美判断力决定了其研究所能企及的高度。”
这一段落所说的Taste,和上一段落说的厚薄,都像是某种“直觉”。用爱因斯坦的话来说:
“真正有价值的是直觉。在探索的道路之上,智力作用不大。”
这种直觉,也是他眼中“由哲学的洞察力所创造的独立性”,能够帮助科学家避免陷入“见树不见林”,爱因斯坦认为这“正是一个工匠或专家,与一个真正的真理追寻者之间,最大的区别。”
看起来,不管是厚薄,还是Taste,都是某种只可意会不能言传的东西。
那么,机器智能是如何感知围棋的“厚薄”的?早在2016年,阿尔法狗已经碾压了人类自以为无法被超越的“灵性”。
起初,计算机像是一种纯粹的基于逻辑推理的机器,直至不确定性和随机性被引入。
辛顿的玻尔兹曼机代表了人工智能发展中的一次关键突破。
最早的神经网络,如霍普菲尔德网络,更多是基于确定性原理来处理信息,擅长记忆和补全任务。
它通过逐步最小化能量进入“能量井”,达到记忆模式的重现。
然而,这类网络的局限在于,它们只能处理已经学习过的模式,而无法创造新的模式,也无法理解数据的内在结构。
他提出的玻尔兹曼机通过模拟物理系统中粒子的随机运动,捕捉数据的概率分布,从而生成新的数据。
这个系统不再总是选择最低能量状态,而是根据波尔兹曼分布,概率性地做出决定。
这一创新让机器学习模型从固定的逻辑跳跃到灵活的随机领域,就像爵士乐手能够在固定的音乐结构中即兴创作。
在物理学中,路德维希·波尔兹曼通过研究气体分子运动中的能量分布,提出了著名的波尔兹曼分布。
他发现,物理系统中低能量状态的粒子比高能量状态的粒子出现的概率更大,这种概率与粒子的能量成指数关系。
简单来说,系统中更稳定的状态出现的概率更大,而高能量状态虽然可能出现,但频率较低。
这一观点将随机性带入了物理学核心概念。波尔兹曼解释了为什么在微观层面上,粒子之间的碰撞会导致能量的分布不均匀,进一步揭示了宏观系统中的不确定性。
这为量子力学中的概率解释奠定了基础。量子世界中的每个事件都遵循某种概率规律,精确预测每个单独事件几乎不可能,但可以通过概率统计对整体行为进行推测。
这种随机性也渗透到了社会和金融领域。塔勒布的第一本书就叫《随机漫步的傻瓜》。
在人生中,随机性也扮演着关键角色。正如人类无法预知未来的一切细节,我们的命运也往往受到各种随机因素的影响。
真正的智慧不是消除不确定性,而是在升维思考中拥抱随机性,借助概率找到那个最佳行动方案。
“按照常规的理解,逻辑要求关于世界的认知是确定的,而实际上这很难实现......概率(probability)论填补了这一鸿沟,允许我们在掌握不确定信息的情况下进行严格的推理。”
也许随机性带来了混乱,带来了不安,但是,随机性也是生命之源,是能量之本吗,甚至也是时间的秘密。
假如热力学第二定律决定了孤立系统会自发地朝着最大熵状态演化,为什么地球上会出现生命?为什么人的大脑能够以如此复杂的机制去思考宇宙?
大的涨落可以造成熵很低的状态,概率也很低,但在宇宙广阔尺度下仍然会发生,而我们自身的存在也是来源于这种涨落带来的低熵世界。
一个奇怪的演绎是:如果宇宙可以通过某种随机波动从虚无中冒出来,那么相比之下,更简单的东西,比如一个大脑,随机出现的可能性会更大。
想象一下,你正坐在沙发上刷这篇文章,感觉一切都很真实。
可根据“玻尔兹曼大脑”的假设,你有可能根本不在客厅里,也没有在看电影。你只是一个孤立的大脑,突然从虚无中“蹦”出来,带着完整的记忆和感知。
尽管这个大脑只会存在极短的时间,然后很快消失,但在那短暂的一瞬间,它坚信自己正处于一个完整的、真实的世界里——正在和舒适的沙发上享受本文的摧残,然而这一切只是大脑的幻觉。
另外一个悬念是:随机涨落中生成的人类,有机会更长久地避开熵增定律,逃离死寂的命运,去宇宙深处探寻秘密吗?
请AI帮我为本文总结出10条有价值的思考工具和行动指南--虽然有点儿多余。
在遇到复杂问题时,引入额外的维度(如时间、温度、空间)帮助你从多个角度进行分析。就像在毒酒问题中从二维升到三维,再到“七维”,增加维度可以发现更多的信息和解决方法。
在面对复杂问题时,降维行动不仅是简化思维,而是基于对全局的深刻理解,将冗余信息压缩,保留最核心的要素。
就像奥卡姆剃刀的原则——去除不必要的假设,选择最简洁的路径。
通过全局的思考做出局部的行动决策,确保简化后的方案依然有效并且精准,避免因过度复杂而拖延或增加不必要的风险。
通过积累知识、体验和反思,逐步建立对事物的“感觉”,培养你自己的Taste。
Taste 是判断力的高维版本,能够帮助你迅速分辨重要信息,提升你的洞察力和决策效率。
现实中常存在不确定性,采用概率思维可以帮助你在不确定中找到最优方案。通过贝叶斯推理或随机策略,训练自己根据有限信息做出合理的推断,并拥抱不确定性。
在深度学习中,权重更新通过反向传播不断调整模型,使其表现越来越好。
类似地,我们在生活中的每一次尝试、成功或失败,都可以视为对自我权重的“更新”,通过不断反思和调整行为策略,优化自己。
将每一次失败视为反向传播的反馈,不断调整你的思维和行动模式。以成长为目标,注重逐步优化,而不是寻求一次性的成功。
利用变化中的机会随机性不仅是混乱的来源,也是机遇的来源。
在你的工作和生活中,适当引入随机性的概念,在多种可能性中大胆尝试,利用“涨落”带来的突破,找到隐藏的解决方案。
在行动时,不要追求最完美的选择,减少不必要的思维复杂性。类似于李昌镐在领先时缩短战线的做法,锁定目标后迅速行动,避免过度优化带来的拖延。
通过观察事物在时间上的变化来做出判断,将时间因素融入决策,提升长远的判断力。
9、可操作的二进制思维:把所有复杂难题简化为二选一
学习二进制的思维模式,帮助你在复杂情况下简化决策。通过将问题拆解为“是/否”、“0/1”形式,快速找到核心点,这种思维方式有助于提升处理复杂问题的效率。
大模型时代,人类最强的能力是提问。培养提出优质问题的能力。让AI帮助你在探索过程中找到突破点。
也许你还记得本文以盲人的难题开头,请允许我用盲人的故事结尾。
盲人失去了观察这个世界最重要的维度之一:视觉。这是普通人无法理解的沉重和不公。
一个人处在这样一个黑暗的、无声的世界里,该如何活下去?
我想分享的故事的主角是海伦·亚当斯·凯勒,她在19个月大的一次疾病中失去了视力和听力。
1924年2月1日,纽约的WEAF广播电台播出了纽约交响乐团现场演奏的贝多芬第九交响曲。
后来她写信给纽约爱乐,分享了自己的体验。以下是该信。
虽然我既瞎且聋,我仍然怀着欢跃之情告诉你们:昨晚我度过一段光辉灿烂的时光,靠着收音机聆听了贝多芬的《第九交响曲》。
我并不是说像其他人一样“听到”音乐;我也不知道是否能让你们了解,我如何能从交响曲得到快乐。这连我自己都惊讶不已。
我早已从杂志上读到收音机带给盲者的幸福:它能带领看不见的人到任何地方去。
我很高兴知道盲者获得了新的乐趣来源;但我从未梦想能得到和他们一样的快乐。
昨晚,当家人聆听你们精彩的演出这不朽的交响曲时,有人建议我把手放在收音机上,看看我能不能感受到任何各式各样的震动。
他旋开收音机的喇叭盖,于是我轻轻碰触敏感的震动膜。我惊奇地发现我能感受到的不只是震动,而且是充满热情的节奏、以及音乐的悸动和涌荡!发自各种不同乐器的震动交缠并融合在一起,使我陶醉不已。
我能确切分辨短号、急切的鼓声、低音的中提琴和优雅合奏的小提琴。当小提琴淹漫并钻犁过其它乐器的最低音调时,它的演奏是多么地美妙!
当人声从和声的波涛中颤栗跃出时,我马上分辨出它们是更加狂喜、迅速上扬如燃烧的火焰,直令我的心跳嘎然而止。
而女声部的歌声似乎具备了天使般的声响,在美丽而鼓舞人的声音洪流中和谐涌动。
接着所有的乐器和人声一起爆发出来——像在天堂摇荡的海洋——然后像风一样渐微渐消,于甜蜜音符的柔和沐浴中结束。
当然这不是“聆听”,但我确知这些音符与和声传达给我雄美和壮丽的情愫。同时我感受到——或者我自认为感受到——自然的温柔歌声唱进我手中;感受到摇摆的芦苇和风、以及潺潺的溪流。我以前从未因这么多的音调震动而狂喜过。
当我聆听时,黑暗和旋律、阴影和声音充满整个房间,我忍不住想到倾注如此甜蜜洪流给世界的这位作曲家,竟是和我一样耳朵聋了。我惊讶于他不灭的精神所产生的力量,从他的痛苦中为别人粹练出欢乐——而我坐在这儿,用我的手感受这神奇的交响曲,仿佛海洋一般拍击着他和我两人寂静的灵魂海岸。
为什么失去了观察世界的很多个维度,海伦·凯勒依然比绝大多数健全的人更能感知这个世界的秘密?
“世界上最好和最美的东西是看不到也摸不到的……它们只能被心灵感受到。”
┌
朴谷咨询(PGA)是一家聚焦于高科技、先进制造、新能源医疗、互联网、消费、教育、文娱等行业,为客户提供投融资尽职调查、融资与并购交易顾问、商业评估、股权激励、财税咨询、资本市场和ESG等服务的专业机构。
朴谷已累计服务超过1000个投融资与并购交易案例,服务美国与香港上市公司超100家,服务美元与人民币投资机构近100家。我们的专业顾问人员分布在北京、上海、杭州、武汉、深圳等多地,均拥有丰富的专业与行业经验,为客户提供最具增值性的专业化服务,深度服务于中国本土资本市场。